
Turning the Tide: Repository-based Code Reflection
Abstract
Code large language models (LLMs) enhance programming by understanding and generating code across languages, offering intelligent feedback, bug detection, and code updates through reflection, improving development efficiency and accessibility. While benchmarks (e.g. HumanEval/LiveCodeBench) evaluate code generation and real-world relevance, previous works ignore the scenario of modifying code in repositories. Considering challenges remaining in improving reflection capabilities and avoiding data contamination in dynamic benchmarks, we introduce LiveRepoReflection, a challenging benchmark for evaluating code understanding and generation in multi-file repository contexts, featuring 1,888 rigorously filtered test cases across 6 programming languages to ensure diversity, correctness, and high difficulty. Further, we create RepoReflection-Instruct, a large-scale, quality-filtered instruction-tuning dataset derived from diverse sources, used to train RepoReflectionCoder through a two-turn dialogue process involving code generation and error-driven repair. The leaderboard evaluates over 40 LLMs to reflect the model performance of repository-based code reflection.
Overview
Code large language models (LLMs) represent a significant advancement in comprehending and producing code across numerous programming languages. Fueled by extensive training on massive code repositories, LLMs empower developers by offering intelligent feedback, identifying potential bugs, and updating code snippets from human instructions. Code reflection refers to the ability of LLMs to examine and modify their previous responses. Using reflection, LLMs can streamline the development process, boost efficiency, and make programming more accessible to a wider number of developers.
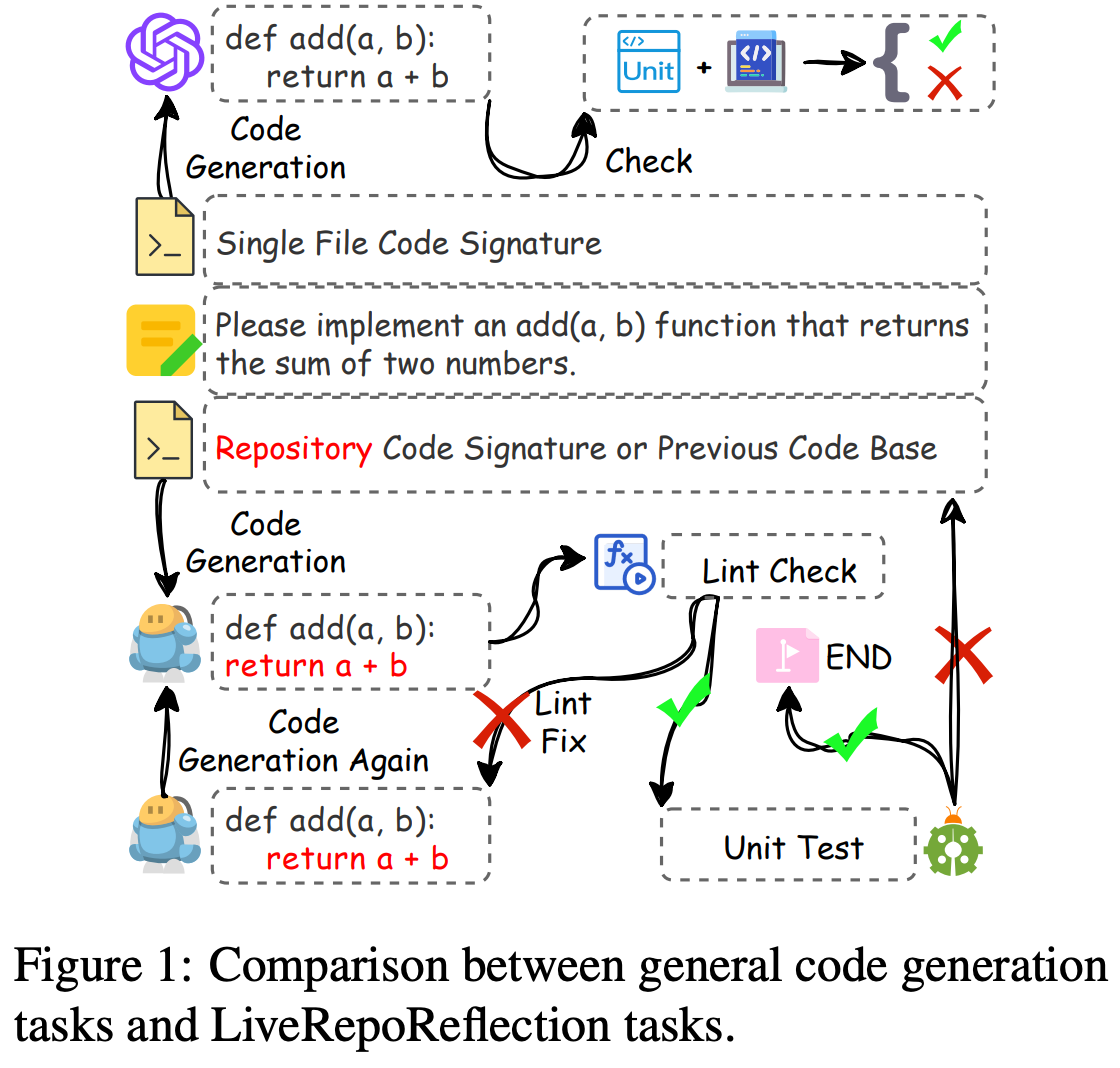
Comparison between general code generation tasks and LiveRepoReflection tasks.
LiveRepoReflection Benchmark
A challenging benchmark for evaluating code understanding and generation in multi-file repository contexts, featuring 1,888 rigorously filtered test cases across 6 programming languages (Python, Java, C++, Rust, Go, JavaScript) to ensure diversity, correctness, and high difficulty.
RepoReflection-Instruct Dataset
A large-scale, quality-filtered instruction-tuning dataset derived from diverse sources including newly automatically generated examples. The dataset was created using sophisticated quality filtering mechanisms and decontamination techniques.
RepoReflectionCoder Model
A specialized LLM trained on the RepoReflection-Instruct dataset through a two-turn dialogue process involving code generation and error-driven repair, with enhanced capabilities for repository-based code reflection.
Comprehensive Evaluation
Systematic evaluation of over 40 LLMs on the LiveRepoReflection benchmark, creating a dynamic leaderboard to track model performance and measuring alignment between model-generated responses and human preferences.
Key Contributions
- High-Quality Benchmark: We propose a high-quality, high-difficulty benchmark for evaluating code reflection of LLMs, featuring 1,888 rigorously filtered test cases across 6 programming languages. The benchmark emphasizes diversity, correctness, and challenge by retaining only cases that stump strong LLMs and undergo human annotation.
- Structured Dataset Creation: Starting with 500k examples, a strict rejection sampling process ensured high quality by filtering repositories based on criteria such as having unit-test files, reference answer files, aligned code signatures and answers, compatible environment configurations, and standardized file names.
- Systematic Evaluation: Our systematic evaluation of over 40+ LLMs on LiveRepoReflection led to the creation of a dynamic leaderboard to track model performance, with extensive experiments demonstrating that LiveRepoReflection effectively measures the alignment between model-generated responses and human preferences.
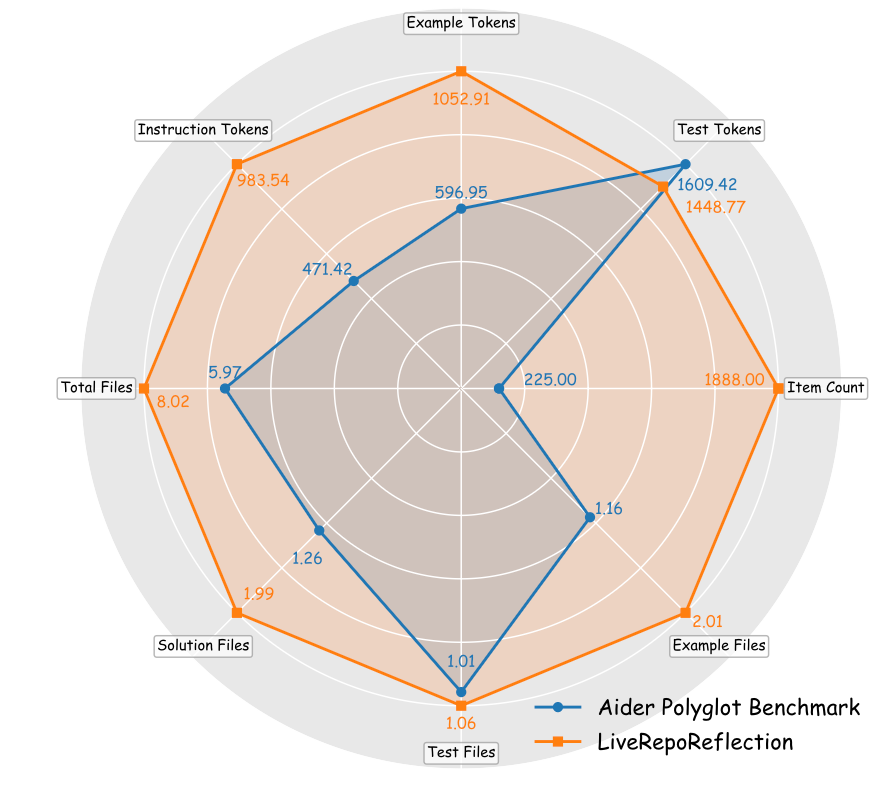
Comparison of dataset scales and structures between Aider Polyglot Benchmark and LiveRepoReflection.
Pipeline Overview
The paper introduces an automatic creation pipeline to dynamically update the large-scale instruction corpus and evaluation benchmark to avoid data hacking:
- Repository structure design: Standardized repository code data file structure designed to be streamlined while ensuring normal evaluation.
- Seed code data collection: High-quality, diverse code samples collected from multiple public sources like GitHub, Hugging Face, and Reddit.
- Multiple-turn dialogue data generation: Using a mix of "creative" and "reasoning" LLMs to generate program topics, definitions, unit tests, and reference answers.
- Cross-execution verification: Rigorous testing and validation to ensure correctness and appropriate difficulty.
- Human annotation: Final validation and refinement by trained annotators to ensure quality.
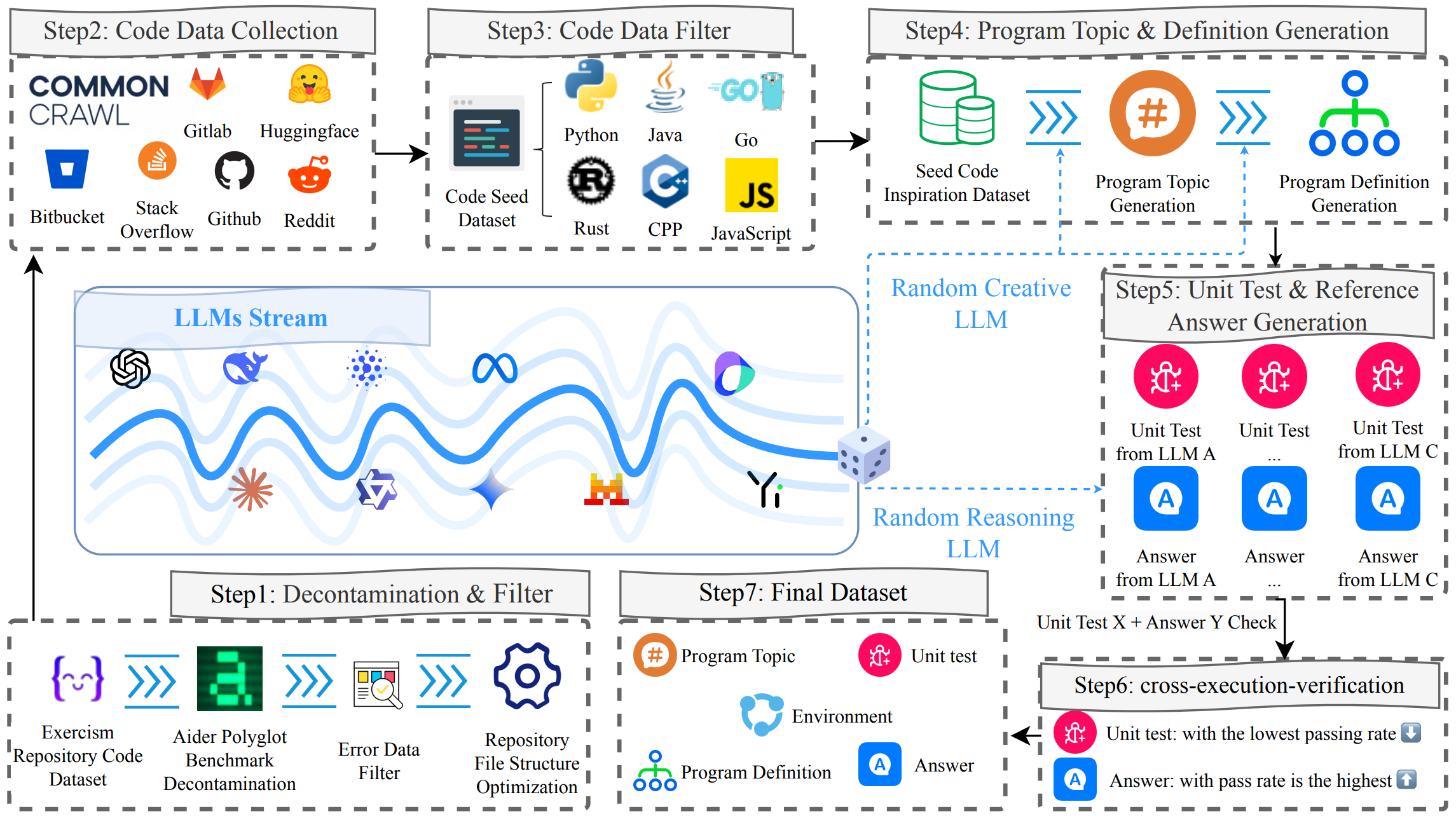
Overview of Construction Pipeline.
Evaluation Edit Format
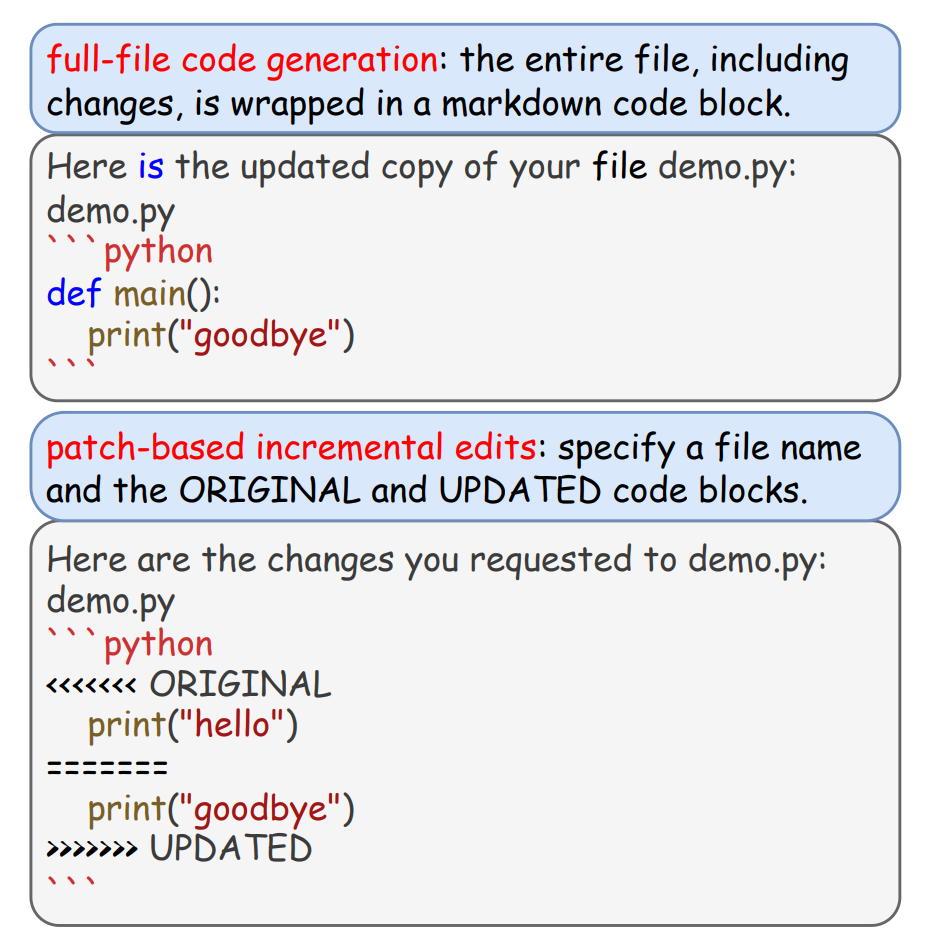
Two evaluation edit format of LiveRepoReflection.
Comparison with Aider Polyglot
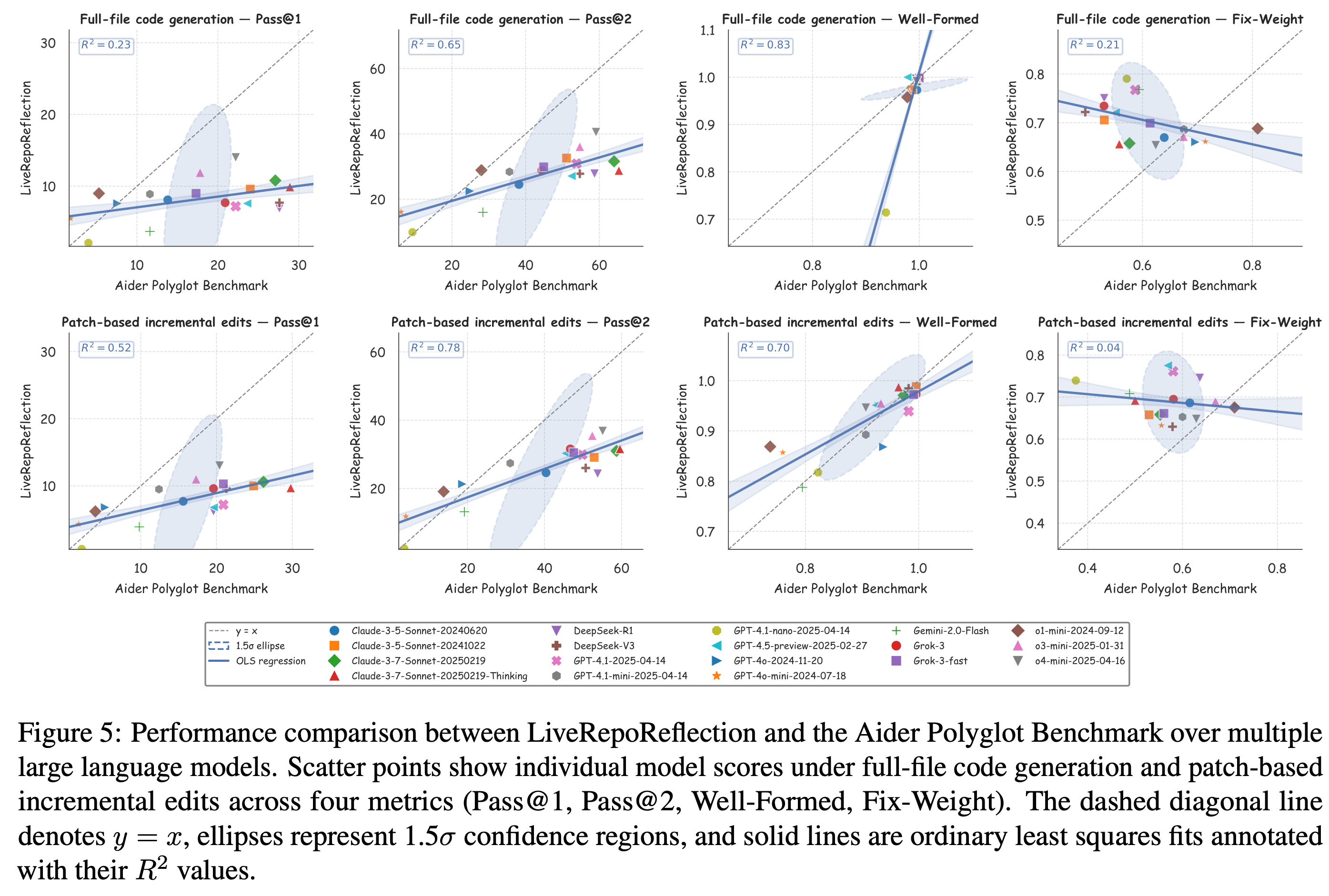
Performance comparison between LiveRepoReflection and the Aider Polyglot Benchmark.
Pass@k Analysis
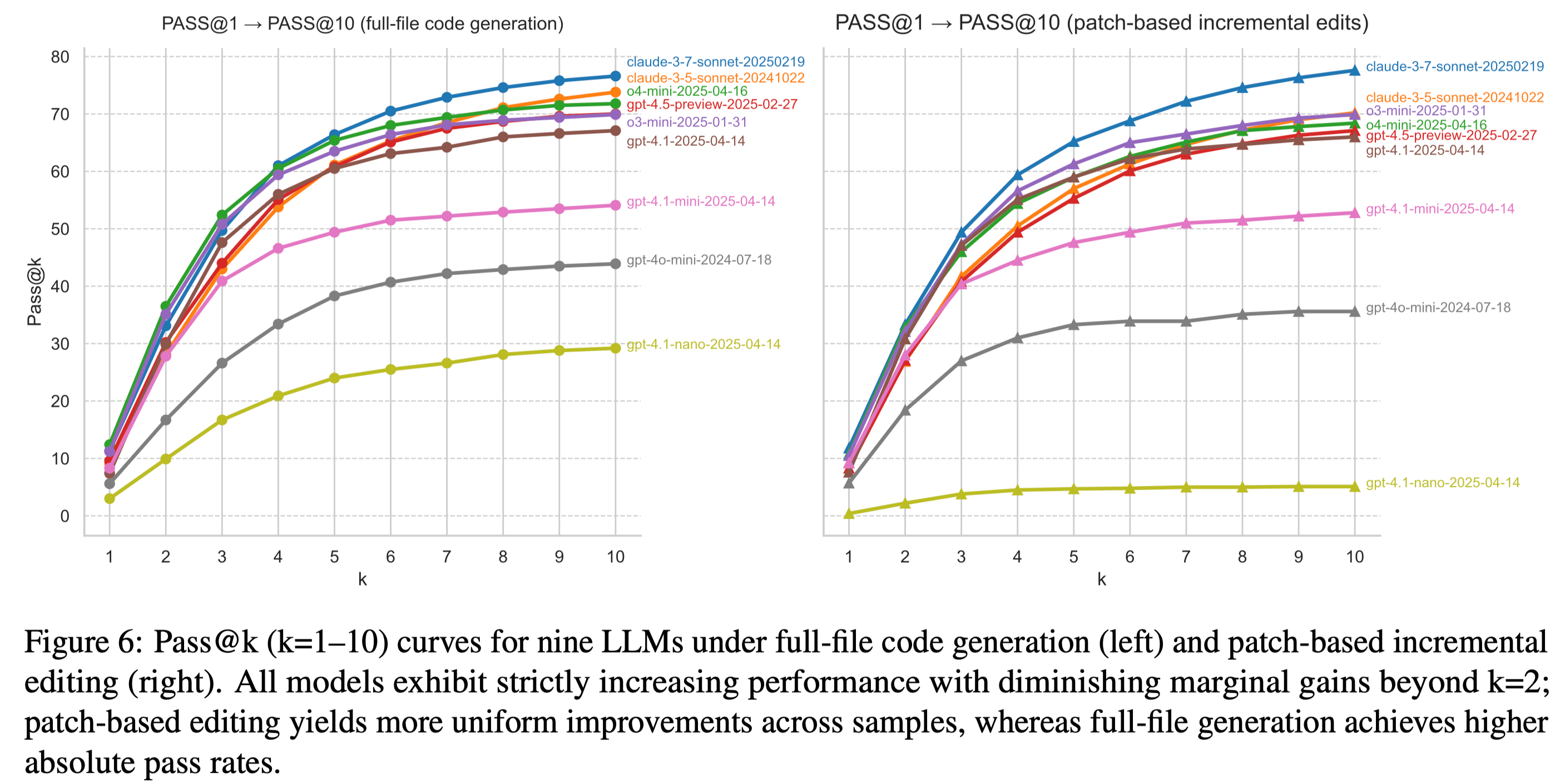
Pass@k (k=1–10) curves for nine LLMs.
File Structure
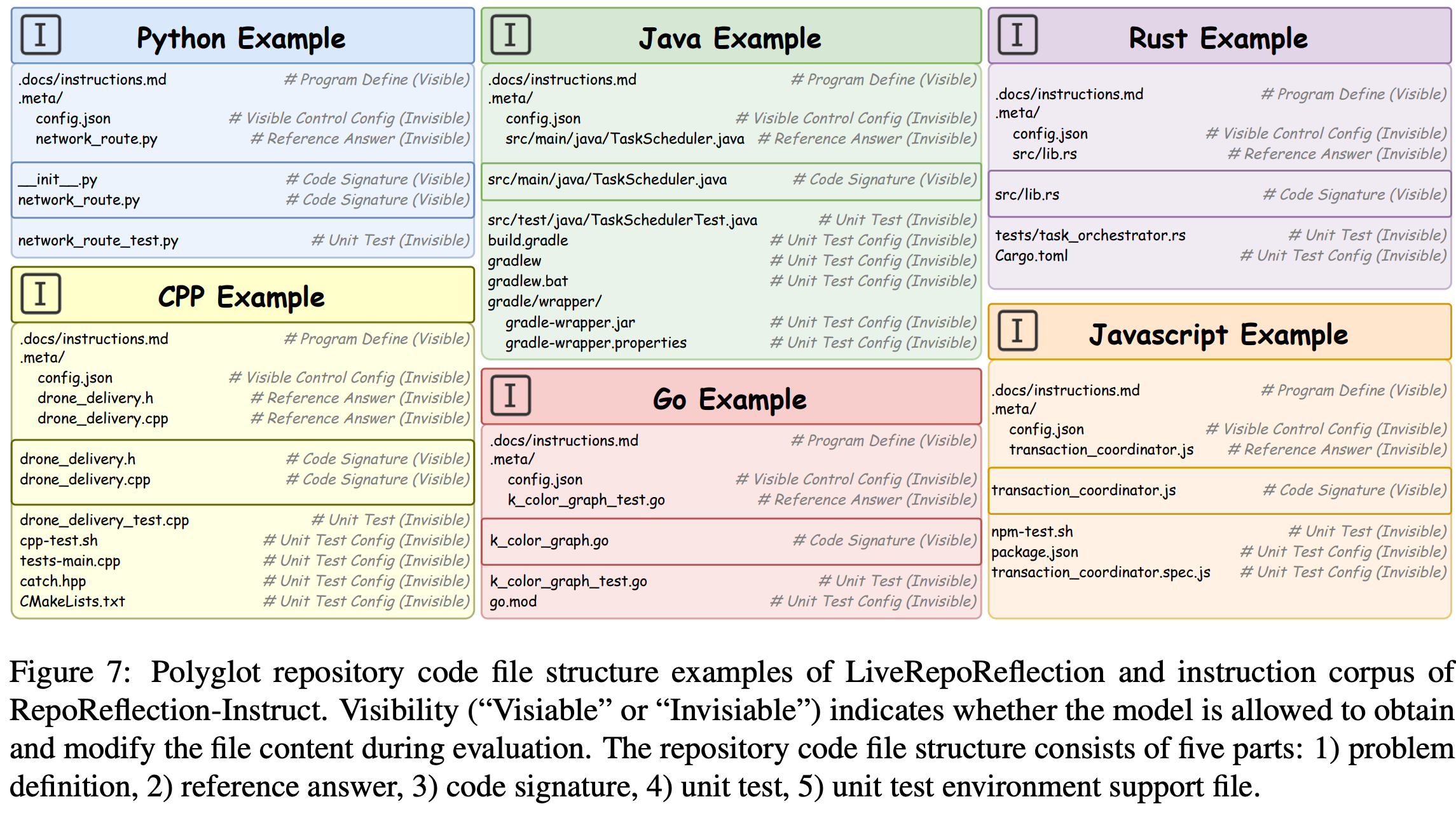
Polyglot repository code file structure examples.